Working with large tables
Source:vignettes/working_with_large_tables.Rmd
working_with_large_tables.RmdMost StatCan tables are small in size and can easily processed in
memory. However, some tables are so large that this is not a feasible
strategy. Table 43-10-0024 is one such example and comes
with a CSV file that is several gigabytes in size. In cases like this it
is more useful to store and access the data as a parquet, feather, or
SQLite database format using the get_cansim_connection
function instead of the usual get_cansim. In these
circumstances it is also useful to cache the data for longer than just
the current R session, and the data_cache option allows to
specify a permanent location. It defaults to the
CANSIM_CACHE_PATH environment variable. It is recommended
to set this in the .Renviron file so it’s accessible in all
R sessions, the set_cansim_cache_path() function
facilitates that and allows for installing this permanently via the
install=TRUE option. If the environment variable is not set
the package will only cache the data for the duration of the current
session.
For this vignette we use the (rather small) motor vehicle sales data as an example.
One main difference to the get_cansim method is that
get_cansim_connection does not return data but only a
connection to the database. This allows us to filter the data before
fetching the data into memory. The package supports three formats with
different advantages and disadvantages:
-
parquet: This is the most efficient format for importing and storing data, but a bit slower when filtering and reading data. -
feather: This is a somewhat less efficient format for importing and storing data, but slightly faster than parquet when filtering and reading data. -
sqlite: This is fairly inefficient format for importing and storing data, taking a lot more disk space, time and a little more memory when importing and indexing, but after importing it allows for very efficient queries and filtering, and additionally allows for database level summary statistics.
By default get_cansim_connection uses the
parquet data format as the best all-around solution, but in use
cases of infrequently updating tables with lots of database queries in
the meantime that need to be fast, and possibly the need for database
level statistics, the sqlite format is likely preferable.
When accessing cached data the package automatically checks if newer
versions are available and issues a warning if the cached version is out
of date. The auto_update argument can be set to
TRUE to automatically refresh the table if needed, or this
can be done manually by setting the refresh argument to
TRUE when calling the function to force a refresh.
Working with cached tables
If data is not cached the function will download the data first and convert it to the specified format. The package is designed so that the differences in database formats are mostly abstracted away.
To make good use of the data we will have to look at the metadata and inspect the member columns and variables available.
This gives us an understanding of the available variables. For the purpose of this vignette we are interested in the breakdown of sales units by Vehicle type in Canada overall. The data is stored in its raw form in the database, the only processing done is that it is augmented by the GeoUID.
connection.parquet <- get_cansim_connection("20-10-0001") # format='parquet' is the default
#> Accessing CANSIM NDM product 20-10-0001 from Statistics Canada
#> Parsing data to parquet.
glimpse(connection.parquet)
#> FileSystemDataset with 1 Parquet file
#> 163,410 rows x 19 columns
#> $ REF_DATE <string> "1946-01", "1946-01", "1946-01", "1946-01", "…
#> $ GEO <string> "Canada", "Canada", "Canada", "Canada", "Cana…
#> $ DGUID <string> "2016A000011124", "2016A000011124", "2016A000…
#> $ `Vehicle type` <string> "Total, new motor vehicles", "Total, new moto…
#> $ `Origin of manufacture` <string> "Total, country of manufacture", "Total, coun…
#> $ Sales <string> "Units", "Dollars", "Units", "Units", "Dollar…
#> $ `Seasonal adjustment` <string> "Unadjusted", "Unadjusted", "Unadjusted", "Se…
#> $ UOM <string> "Units", "Dollars", "Units", "Units", "Dollar…
#> $ UOM_ID <string> "300", "81", "300", "300", "81", "300", "300"…
#> $ SCALAR_FACTOR <string> "units", "thousands", "units", "units", "thou…
#> $ SCALAR_ID <string> "0", "3", "0", "0", "3", "0", "0", "3", "0", …
#> $ VECTOR <string> "v42169911", "v42169913", "v42169920", "v4216…
#> $ COORDINATE <string> "1.1.1.1.1", "1.1.1.2.1", "1.2.1.1.1", "1.2.1…
#> $ VALUE <double> 2756, 4507, 1102, 1468, 1604, 1654, 2037, 290…
#> $ STATUS <string> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
#> $ SYMBOL <string> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
#> $ TERMINATED <string> NA, NA, NA, "t", NA, NA, "t", NA, NA, NA, NA,…
#> $ DECIMALS <string> "0", "0", "0", "0", "0", "0", "0", "0", "0", …
#> $ GeoUID <string> "11124", "11124", "11124", "11124", "11124", …
#> Call `print()` for full schema details
connection.feather <- get_cansim_connection("20-10-0001", format='feather')
#> Accessing CANSIM NDM product 20-10-0001 from Statistics Canada
#> Parsing data to feather.
glimpse(connection.feather)
#> FileSystemDataset with 1 Feather file
#> 163,410 rows x 19 columns
#> $ REF_DATE <string> "1946-01", "1946-01", "1946-01", "1946-01", "…
#> $ GEO <string> "Canada", "Canada", "Canada", "Canada", "Cana…
#> $ DGUID <string> "2016A000011124", "2016A000011124", "2016A000…
#> $ `Vehicle type` <string> "Total, new motor vehicles", "Total, new moto…
#> $ `Origin of manufacture` <string> "Total, country of manufacture", "Total, coun…
#> $ Sales <string> "Units", "Dollars", "Units", "Units", "Dollar…
#> $ `Seasonal adjustment` <string> "Unadjusted", "Unadjusted", "Unadjusted", "Se…
#> $ UOM <string> "Units", "Dollars", "Units", "Units", "Dollar…
#> $ UOM_ID <string> "300", "81", "300", "300", "81", "300", "300"…
#> $ SCALAR_FACTOR <string> "units", "thousands", "units", "units", "thou…
#> $ SCALAR_ID <string> "0", "3", "0", "0", "3", "0", "0", "3", "0", …
#> $ VECTOR <string> "v42169911", "v42169913", "v42169920", "v4216…
#> $ COORDINATE <string> "1.1.1.1.1", "1.1.1.2.1", "1.2.1.1.1", "1.2.1…
#> $ VALUE <double> 2756, 4507, 1102, 1468, 1604, 1654, 2037, 290…
#> $ STATUS <string> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
#> $ SYMBOL <string> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
#> $ TERMINATED <string> NA, NA, NA, "t", NA, NA, "t", NA, NA, NA, NA,…
#> $ DECIMALS <string> "0", "0", "0", "0", "0", "0", "0", "0", "0", …
#> $ GeoUID <string> "11124", "11124", "11124", "11124", "11124", …
#> Call `print()` for full schema details
connection.sqlite <- get_cansim_connection("20-10-0001", format='sqlite')
#> Accessing CANSIM NDM product 20-10-0001 from Statistics Canada
#> Parsing data to sqlite.
#> Indexing GEO
#> Indexing Vehicle type
#> Indexing Origin of manufacture
#> Indexing Sales
#> Indexing Seasonal adjustment
#> Indexing REF_DATE
#> Indexing DGUID
#> Indexing GeoUID
glimpse(connection.sqlite)
#> Rows: ??
#> Columns: 19
#> Database: sqlite 3.50.1 [/Users/jens/data/cansim.data/cansim_20100001_sqlite_eng/20100001-eng.sqlite]
#> $ REF_DATE <chr> "1946-01", "1946-01", "1946-01", "1946-01", "1…
#> $ GEO <chr> "Canada", "Canada", "Canada", "Canada", "Canad…
#> $ GeoUID <chr> "11124", "11124", "11124", "11124", "11124", "…
#> $ DGUID <chr> "2016A000011124", "2016A000011124", "2016A0000…
#> $ `Vehicle type` <chr> "Total, new motor vehicles", "Total, new motor…
#> $ `Origin of manufacture` <chr> "Total, country of manufacture", "Total, count…
#> $ Sales <chr> "Units", "Dollars", "Units", "Units", "Dollars…
#> $ `Seasonal adjustment` <chr> "Unadjusted", "Unadjusted", "Unadjusted", "Sea…
#> $ UOM <chr> "Units", "Dollars", "Units", "Units", "Dollars…
#> $ UOM_ID <chr> "300", "81", "300", "300", "81", "300", "300",…
#> $ SCALAR_FACTOR <chr> "units", "thousands", "units", "units", "thous…
#> $ SCALAR_ID <chr> "0", "3", "0", "0", "3", "0", "0", "3", "0", "…
#> $ VECTOR <chr> "v42169911", "v42169913", "v42169920", "v42169…
#> $ COORDINATE <chr> "1.1.1.1.1", "1.1.1.2.1", "1.2.1.1.1", "1.2.1.…
#> $ VALUE <dbl> 2756, 4507, 1102, 1468, 1604, 1654, 2037, 2903…
#> $ STATUS <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
#> $ SYMBOL <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
#> $ TERMINATED <chr> NA, NA, NA, "t", NA, NA, "t", NA, NA, NA, NA, …
#> $ DECIMALS <chr> "0", "0", "0", "0", "0", "0", "0", "0", "0", "…Filtering and loading into memory
In order to work with the data we need to load it into memory, which
is done calling collect() on the connection object. If we
want to make use of the additional metadata and processing the
cansim package usually does and the main operations done on the
connection were filtering (and not renaming or de-selecting columns
needed for enriching with metadata) then we can utilize the custom
collect_and_normalize function to do this and at the same
time normalize the data so it will appear the same way as if we had used
the get_cansim function. This will add the category and
hierarchy metadata and the normalized value column. In the case of
sqlite connections we might want to pass the
disconnect = TRUE argument in the
collect_and_normalize function to close the connection
after normalizing the data, or do that manually at a later time via
disconnect_cansim_sqlite(connection). This is not required
for parquet or feather connections.
The collect_and_normalize() interface is designed to be
used in the same way across database formats. In this comparison we also
add the “traditional” get_cansim() approach that reads the
entire table into memory and normalizes the data.
data.parquet <- connection.parquet %>%
filter(GEO=="Canada",
`Seasonal adjustment`=="Unadjusted",
Sales=="Units",
`Origin of manufacture`=="Total, country of manufacture",
`Vehicle type` %in% c("Passenger cars","Trucks")) %>%
collect_and_normalize()
data.parquet %>% head()
#> # A tibble: 6 × 30
#> REF_DATE Date GEO DGUID GeoUID `Vehicle type` Origin of manufactur…¹
#> <chr> <date> <fct> <chr> <chr> <fct> <fct>
#> 1 1975-11 1975-11-01 Canada 2016A… 11124 Passenger cars Total, country of man…
#> 2 1975-11 1975-11-01 Canada 2016A… 11124 Trucks Total, country of man…
#> 3 1975-12 1975-12-01 Canada 2016A… 11124 Passenger cars Total, country of man…
#> 4 1975-12 1975-12-01 Canada 2016A… 11124 Trucks Total, country of man…
#> 5 1976-01 1976-01-01 Canada 2016A… 11124 Passenger cars Total, country of man…
#> 6 1976-01 1976-01-01 Canada 2016A… 11124 Trucks Total, country of man…
#> # ℹ abbreviated name: ¹`Origin of manufacture`
#> # ℹ 23 more variables: Sales <fct>, `Seasonal adjustment` <fct>, VALUE <dbl>,
#> # val_norm <dbl>, UOM <chr>, UOM_ID <chr>, SCALAR_FACTOR <chr>,
#> # SCALAR_ID <chr>, VECTOR <chr>, COORDINATE <chr>, STATUS <chr>,
#> # SYMBOL <chr>, TERMINATED <chr>, DECIMALS <chr>, `Hierarchy for GEO` <chr>,
#> # `Classification Code for Vehicle type` <chr>,
#> # `Hierarchy for Vehicle type` <chr>, …
data.feather <- connection.feather %>%
filter(GEO=="Canada",
`Seasonal adjustment`=="Unadjusted",
Sales=="Units",
`Origin of manufacture`=="Total, country of manufacture",
`Vehicle type` %in% c("Passenger cars","Trucks")) %>%
collect_and_normalize()
data.feather %>% head()
#> # A tibble: 6 × 30
#> REF_DATE Date GEO DGUID GeoUID `Vehicle type` Origin of manufactur…¹
#> <chr> <date> <fct> <chr> <chr> <fct> <fct>
#> 1 1970-03 1970-03-01 Canada 2016A… 11124 Passenger cars Total, country of man…
#> 2 1970-03 1970-03-01 Canada 2016A… 11124 Trucks Total, country of man…
#> 3 1970-04 1970-04-01 Canada 2016A… 11124 Passenger cars Total, country of man…
#> 4 1970-04 1970-04-01 Canada 2016A… 11124 Trucks Total, country of man…
#> 5 1970-05 1970-05-01 Canada 2016A… 11124 Passenger cars Total, country of man…
#> 6 1970-05 1970-05-01 Canada 2016A… 11124 Trucks Total, country of man…
#> # ℹ abbreviated name: ¹`Origin of manufacture`
#> # ℹ 23 more variables: Sales <fct>, `Seasonal adjustment` <fct>, VALUE <dbl>,
#> # val_norm <dbl>, UOM <chr>, UOM_ID <chr>, SCALAR_FACTOR <chr>,
#> # SCALAR_ID <chr>, VECTOR <chr>, COORDINATE <chr>, STATUS <chr>,
#> # SYMBOL <chr>, TERMINATED <chr>, DECIMALS <chr>, `Hierarchy for GEO` <chr>,
#> # `Classification Code for Vehicle type` <chr>,
#> # `Hierarchy for Vehicle type` <chr>, …
data.sqlite <- connection.sqlite %>%
filter(GEO=="Canada",
`Seasonal adjustment`=="Unadjusted",
Sales=="Units",
`Origin of manufacture`=="Total, country of manufacture",
`Vehicle type` %in% c("Passenger cars","Trucks")) %>%
collect_and_normalize()
data.sqlite %>% head()
#> # A tibble: 6 × 30
#> REF_DATE Date GEO DGUID GeoUID `Vehicle type` Origin of manufactur…¹
#> <chr> <date> <fct> <chr> <chr> <fct> <fct>
#> 1 1946-01 1946-01-01 Canada 2016A… 11124 Passenger cars Total, country of man…
#> 2 1946-01 1946-01-01 Canada 2016A… 11124 Trucks Total, country of man…
#> 3 1946-02 1946-02-01 Canada 2016A… 11124 Passenger cars Total, country of man…
#> 4 1946-02 1946-02-01 Canada 2016A… 11124 Trucks Total, country of man…
#> 5 1946-03 1946-03-01 Canada 2016A… 11124 Passenger cars Total, country of man…
#> 6 1946-03 1946-03-01 Canada 2016A… 11124 Trucks Total, country of man…
#> # ℹ abbreviated name: ¹`Origin of manufacture`
#> # ℹ 23 more variables: Sales <fct>, `Seasonal adjustment` <fct>, VALUE <dbl>,
#> # val_norm <dbl>, UOM <chr>, UOM_ID <chr>, SCALAR_FACTOR <chr>,
#> # SCALAR_ID <chr>, VECTOR <chr>, COORDINATE <chr>, STATUS <chr>,
#> # SYMBOL <chr>, TERMINATED <chr>, DECIMALS <chr>, `Hierarchy for GEO` <chr>,
#> # `Classification Code for Vehicle type` <chr>,
#> # `Hierarchy for Vehicle type` <chr>, …
data.memory <- get_cansim("20-10-0001") %>%
filter(GEO=="Canada",
`Seasonal adjustment`=="Unadjusted",
Sales=="Units",
`Origin of manufacture`=="Total, country of manufacture",
`Vehicle type` %in% c("Passenger cars","Trucks"))
#> Accessing CANSIM NDM product 20-10-0001 from Statistics Canada
#> Parsing data
data.memory %>% head()
#> # A tibble: 6 × 30
#> REF_DATE Date GEO DGUID GeoUID `Vehicle type` Origin of manufactur…¹
#> <chr> <date> <fct> <chr> <chr> <fct> <fct>
#> 1 1946-01 1946-01-01 Canada 2016A… 11124 Passenger cars Total, country of man…
#> 2 1946-01 1946-01-01 Canada 2016A… 11124 Trucks Total, country of man…
#> 3 1946-02 1946-02-01 Canada 2016A… 11124 Passenger cars Total, country of man…
#> 4 1946-02 1946-02-01 Canada 2016A… 11124 Trucks Total, country of man…
#> 5 1946-03 1946-03-01 Canada 2016A… 11124 Passenger cars Total, country of man…
#> 6 1946-03 1946-03-01 Canada 2016A… 11124 Trucks Total, country of man…
#> # ℹ abbreviated name: ¹`Origin of manufacture`
#> # ℹ 23 more variables: Sales <fct>, `Seasonal adjustment` <fct>, VALUE <dbl>,
#> # val_norm <dbl>, UOM <chr>, UOM_ID <chr>, SCALAR_FACTOR <chr>,
#> # SCALAR_ID <chr>, VECTOR <chr>, COORDINATE <chr>, STATUS <chr>,
#> # SYMBOL <chr>, TERMINATED <chr>, DECIMALS <chr>, `Hierarchy for GEO` <chr>,
#> # `Classification Code for Vehicle type` <chr>,
#> # `Hierarchy for Vehicle type` <chr>, …We note that the syntax, and the resulting data frames, are identical.
Working with the data
With all three data formats producing the same output we can now work
with the data as if it was fetched and subsequently filtered via
get_cansim.
Given the data we can further filter the date range and plot it.
data.parquet %>%
filter(Date>=as.Date("1990-01-01")) %>%
ggplot(aes(x=Date,y=val_norm,color=`Vehicle type`)) +
geom_smooth(span=0.2,method = 'loess', formula = y ~ x) +
theme(legend.position="bottom") +
scale_y_continuous(labels = function(d)scales::comma(d,scale=10^-3,suffix="k")) +
labs(title="Canada new motor vehicle sales",caption="StatCan Table 20-10-0001",
x=NULL,y="Number of units")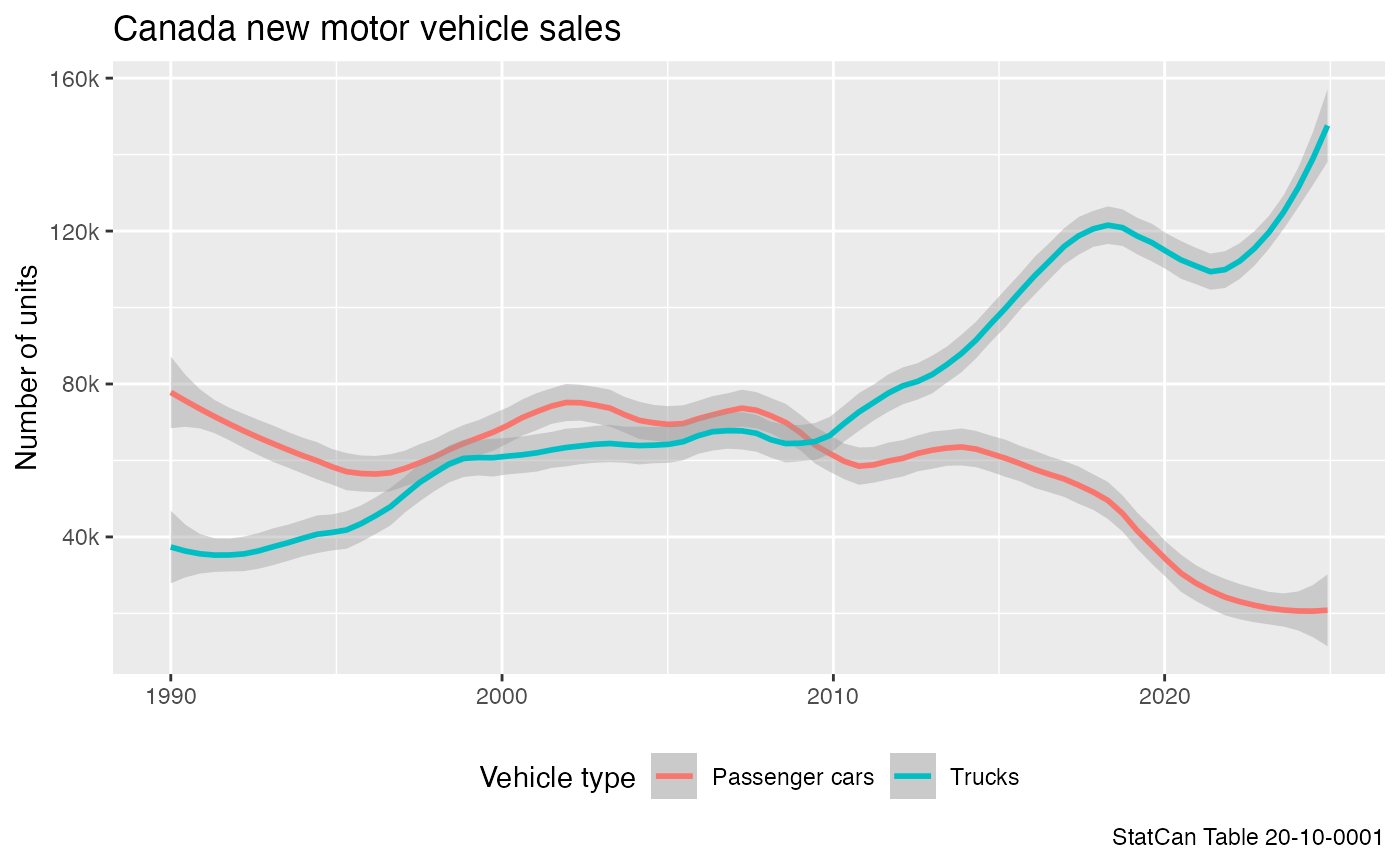
Partitioning
To improve read performance of parquet and feather
data one can specify a partioning argument when calling
get_cansim_connection. This will partition the data by the
specified columns. This can be useful when filtering by these columns as
it will only read the relevant partitions and greatly increase read
performance with a sight cost to size on disk. If for example a dataset
is mostly accessed by filtering on geographic regions, it might be
useful to partition by GeoUID, or the GEO
column if querying data by name. More than one partitioning column can
be specified, but this is only helpful for very large datasets with a
high number of dimensions. A parquet dataset that is
partitioned with the subsequent queries in mind is often faster in data
retrieval than an index SQLite database. The arrow package has
more guidance on partitioning and the tradeoffs.
Repartitioning
Partitioning happens on initial data import and changing the
partitioning parameter in subsequent calls to
get_cansim_connection() won’t have any effect, although a
warning will get issued if the specified partitioning is not empty and
differs from the initial partitioning. In some cases, for example when
doing lots of data queries on the dataset, it might make sense to
occasionally change the partitioning of the data in order to optimize
read performance. This can be done with the
cansim_repartition_cached_table() that takes a
new_partitioning argument. Repartitioning happens fairly
fast, taking up to several seconds on fairly large tables where the
original CSV is several gigabytes in size.
Keeping track of cached data
Since we now have the option of a more permanent cache we should take
care to manage that space properly. The
list_cansim_sqlite_cached_tables function gives us an
overview over the cached data we have.
list_cansim_cached_tables()
#> # A tibble: 60 × 10
#> cansimTableNumber language dataFormat timeCached niceSize rawSize
#> <chr> <chr> <chr> <dttm> <chr> <dbl>
#> 1 11-10-0004 eng parquet 2025-07-18 22:22:12 1.8 Mb 1884578
#> 2 11-10-0008 eng parquet 2025-07-18 23:12:15 14.4 Mb 15047191
#> 3 11-10-0009 eng parquet 2025-07-18 22:06:31 2 Mb 2125776
#> 4 11-10-0009 eng sqlite 1900-01-01 01:00:00 NA NA
#> 5 11-10-0017 eng parquet 2025-02-11 11:49:21 9.3 Mb 9767494
#> 6 11-10-0047 eng parquet 2025-07-15 14:44:05 918 Kb 940072
#> 7 11-10-0191 eng parquet 2025-05-01 13:48:11 12.5 Mb 13142229
#> 8 11-10-0223 eng parquet 2025-05-21 13:12:41 4.2 Mb 4404277
#> 9 11-10-0239 eng parquet 2025-07-18 22:30:23 27.7 Mb 29072464
#> 10 13-10-0418 eng parquet 2025-06-22 15:37:38 18.9 Kb 19367
#> # ℹ 50 more rows
#> # ℹ 4 more variables: title <chr>, path <chr>, timeReleased <dttm>,
#> # upToDate <lgl>Removing cached data
If we want to free up disk space we can remove a cached table or several tables. The following call will remove all cached “20-10-0001” tables in all formats and languages. Before that we disconnect the connection to the sqlite database.
disconnect_cansim_sqlite(connection.sqlite)
remove_cansim_cached_tables("20-10-0001")
#> Removing feather cached data for 20-10-0001 (eng)
#> Removing parquet cached data for 20-10-0001 (eng)
#> Removing sqlite cached data for 20-10-0001 (eng)